java集合高级面试问题(一)
ConcurrentHashMap
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个 ConcurrentHashMap JDK 1.7 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
CocurrentHashMap(JDK 1.8) 抛弃了原有的 Segment 分段锁,采用了 CAS + synchronized 来保证并发安全性。其中的 val next 都用了 volatile 修饰,保证了可见性。
ConcurrentHashMap 在 Java 8 中存在一个 bug 会进入死循环,原因是递归创建 ConcurrentHashMap 对象,但是在 JDK 1.9 已经修复了。
Map<String, Integer> map = new ConcurrentHashMap<>(16);
map.computeIfAbsent(
"AaAa",
key -> {
return map.computeIfAbsent(
"BBBB",
key2 -> 42);
}
);在computeIfAbsent中调用computeIfAbsent的情况下,如果两个key的hashcode相同
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
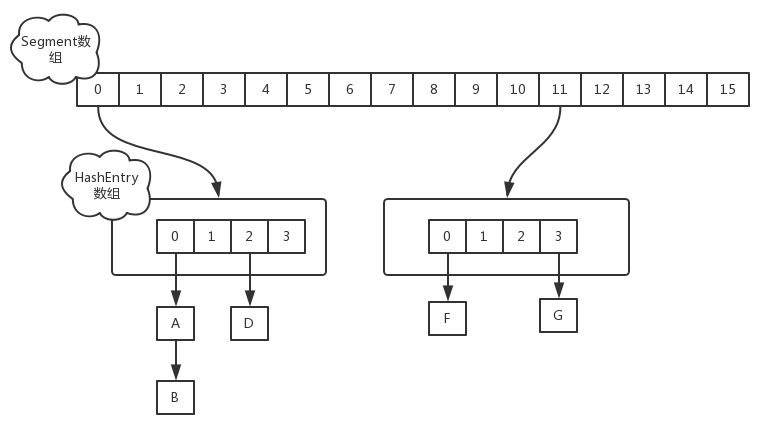
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样.
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本
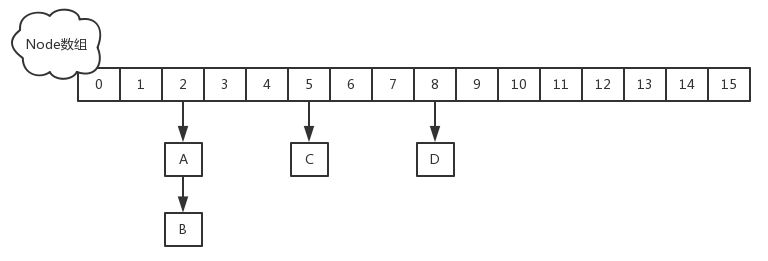
改进一:取消segments字段,直接采用transient volatile HashEntry[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
HashMap
就比如问你 **HashMap 是不是有序的?**你回答不是有序的。
那面试官就会可能继续问你,**有没有有序的Map实现类呢?**你如果这个时候说不知道的话,那这块问题就到此结束了。如果你说有 TreeMap 和 LinkedHashMap。
那么面试官接下来就可能会问你,**TreeMap 和 LinkedHashMap 是如何保证它的顺序的?**如果你回答不上来,那么到此为止。如果你说 TreeMap 是通过实现 SortMap 接口,能够把它保存的键值对根据 key 排序,基于红黑树,从而保证 TreeMap 中所有键值对处于有序状态。LinkedHashMap 则是通过插入排序(就是你 put 的时候的顺序是什么,取出来的时候就是什么样子)和访问排序(改变排序把访问过的放到底部)让键值有序。
拉链法导致的链表过深,为什么不用二叉查找树代替而选择红黑树?为什么不一直使用红黑树?
之所以选择红黑树是为了解决二叉查找树的缺陷:二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成层次很深的问题),遍历查找会非常慢。而红黑树在插入新数据后可能需要通过左旋、右旋、变色这些操作来保持平衡。引入红黑树就是为了查找数据快,解决链表查询深度的问题。我们知道红黑树属于平衡二叉树,为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少。所以当长度大于8的时候,会使用红黑树;如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
说说你对红黑树的见解?
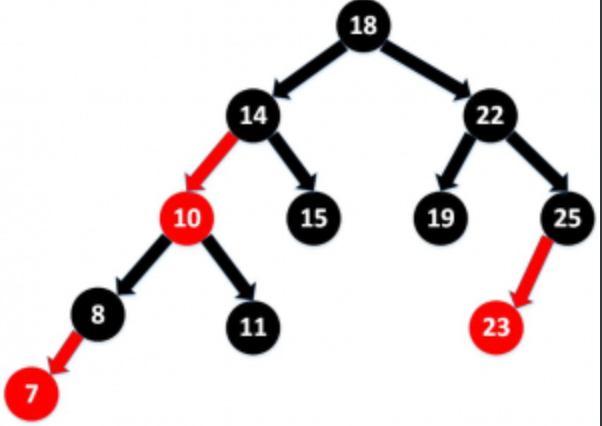
每个节点非红即黑
根节点总是黑色的
如果节点是红色的,则它的子节点必须是黑色的(反之不一定)
每个叶子节点都是黑色的空节点(NIL节点)
从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
重新调整 HashMap 大小存在什么问题吗?
重新调整 HashMap 大小的时候,确实存在条件竞争。
因为如果两个线程都发现 HashMap 需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来。因为移动到新的 bucket 位置的时候,HashMap 并不会将元素放在链表的尾部,而是放在头部。这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。多线程的环境下不使用 HashMap。
JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置
JDK1.8解决了resize时多线程死循环问题,但仍是非线程安全的。
loadFactor: 加载因子,默认是0.75,这个值是经过反复测试最合适的值,当hashmap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,那么当hashmap中元素个数超过160.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍
HashMap初始容量为什么是2的n次幂及扩容为什么是2倍的形式
hashcode的计算:首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&): (n-1) & hashcode
HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;
另外,HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,使得查询效率降低!
HashMap和LinkedHashMap的区别
我们知道HashMap的变量顺序是不可预测的,这意味着便利的输出顺序并不一定和HashMap的插入顺序是一致的。这个特性通常会对我们的工作造成一定的困扰。为了实现这个功能,我们可以使用LinkedHashMap。
LinkedHashMap和HashMap的区别就是新创建了一个Entry,这个Entry继承自HashMap.Node,多了一个before,after来实现Node之间的连接。
通过这个新创建的Entry,就可以保证遍历的顺序和插入的顺序一致。
HashMap和TreeMap的区别
从类的定义来看,HashMap和TreeMap都继承自AbstractMap,不同的是HashMap实现的是Map接口,而TreeMap实现的是NavigableMap接口。NavigableMap是SortedMap的一种,实现了对Map中key的排序。
这样两者的第一个区别就出来了,TreeMap是排序的而HashMap不是。
HashMap的底层是Array,所以HashMap在添加,查找,删除等方法上面速度会非常快。而TreeMap的底层是一个Tree结构,所以速度会比较慢。
另外HashMap因为要保存一个Array,所以会造成空间的浪费,而TreeMap只保存要保持的节点,所以占用的空间比较小。
HashMap如果出现hash冲突的话,效率会变差,不过在java 8进行TreeNode转换之后,效率有很大的提升。
TreeMap在添加和删除节点的时候会进行重排序,会对性能有所影响。
HashMap可以允许一个null key和多个null value。而TreeMap不允许null key,但是可以允许多个null value。
HashTable
数组 + 链表方式存储
默认容量:11(质数为宜)
put操作:首先进行索引计算 (key.hashCode() & 0x7FFFFFFF)% table.length;若在链表中找到了,则替换旧值,若未找到则继续;当总元素个数超过 容量 * 加载因子 时,扩容为原来 2 倍并重新散列;将新元素加到链表头部
对修改 Hashtable 内部共享数据的方法添加了 synchronized,保证线程安全
ArrayList 和 Vector 的区别
这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合, Vector 是线程安全,Vector 增长原来的一倍,ArrayList 增加原来的 0.5 倍。
Arrays.AsList
AsList返回的是一个内部的ArrayList类
Copy ArrayList的四种方式
Arrays.copyOf方法来对数组进行拷贝
List有一个addAll方法,我们可以使用这个方法来进行拷贝
Collections.copy也可以得到相同的效果
使用java 8引入的stream来实现
Iterator to list的三种方法
最简单最基本的逻辑就是使用while来遍历这个Iterator,在遍历的过程中将Iterator中的元素添加到新建的List中去。
Iterator接口有个default方法 ForEachRemaining
将Iterator转换为Iterable,Iterable有个spliterator()的方法返回Spliterator,然后调用StreamSupport的stream方法传入Spliterator进行转换。
Iterator 和 ListIterator 的区别是什么?
ListIterator 是Iterator 的子接口, Iterator 可用来遍历 Set 和 List 集合,但是 ListIterator 只能用来遍历 List。
Iterator 对集合只能是前向遍历,ListIterator 既可以前向也可以后向。
数组 (Array) 和列表 (ArrayList) 有什么区别?什么时候应该使用 Array 而不是 ArrayList?
Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
Array 大小是固定的,ArrayList 的大小是动态变化的。
HashSet中元素重复的判断
先判断hash值,然后判断 == 或者 equals
fail-safe fail-fast知多少
Fail-fast看名字就知道它的意思是失败的非常快。就是说如果在遍历的过程中修改了集合的结构,则就会立刻报错。
我们以ArrayList为例,来讲解下Fail-fast 的原理。
在AbstractList中,定义了一个modCount变量
在遍历的过程中都会去调用checkForComodification()方法来对modCount进行检测
在创建Iterator的时候会复制当前的modCount进行比较,而这个modCount在每次集合修改的时候都会进行变动,最终导致Iterator中的modCount和现有的modCount是不一致的。
Fail-fast并不保证所有的修改都会报错,我们不能够依赖ConcurrentModificationException来判断遍历中集合是否被修改。
我们再来讲一下Fail-safe,Fail-safe的意思是在遍历的过程中,如果对集合进行修改是不会报错的。
Concurrent包下面的类型都是Fail-safe的。
ConcurrentSkipListMap
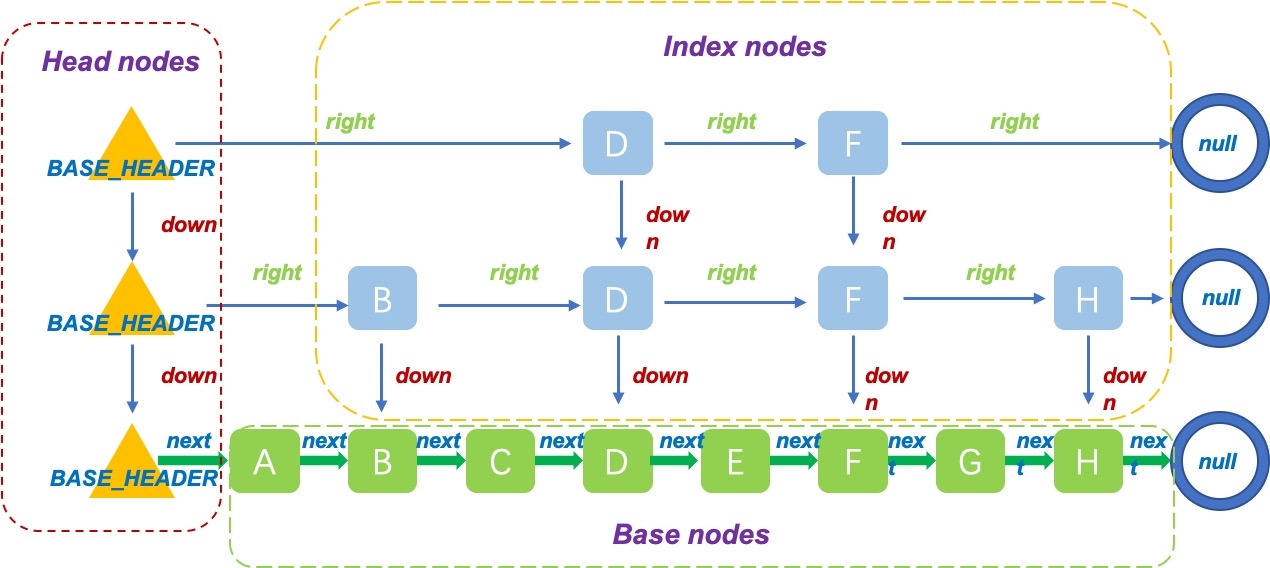
SkipList原来是一种数据结构,而java中的ConcurrentSkipListMap和ConcurrentSkipListSet就是这种结构的实现。
通过使用SkipList,我们构建了多个List,包含不同的排序过的节点,从而提升List的查找效率。
每次的查找都是从最顶层开始,因为最顶层的节点数最少,如果要查找的节点在list中的两个节点中间,则向下移一层继续查找,最终找到最底层要插入的位置,插入节点,然后再次调用概率函数f,决定是否向上复制节点。
Queue
一般来说Queue可以分为BlockingQueue,Deque和TransferQueue三种。
BlockingQueue是Queue的一种实现,它提供了两种额外的功能:
当当前Queue是空的时候,从BlockingQueue中获取元素的操作会被阻塞。
当当前Queue达到最大容量的时候,插入BlockingQueue的操作会被阻塞。
Deque是Queue的子类,它代表double ended queue,也就是说可以从Queue的头部或者尾部插入和删除元素。
TransferQueue继承自BlockingQueue,为什么叫Transfer呢?因为TransferQueue提供了一个transfer的方法,生产者可以调用这个transfer方法,从而等待消费者调用take或者poll方法从Queue中拿取数据。
还提供了非阻塞和timeout版本的tryTransfer方法以供使用。
ArrayBlockingQueue(公平、非公平)
用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列:
LinkedBlockingQueue(两个独立锁提高并发)
基于链表的阻塞队列,同ArrayListBlockingQueue 类似,此队列按照先进先出(FIFO)的原则对元素进行排序。而LinkedBlockingQueue 之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE)。
PriorityQueue和PriorityBlockingQueue
先看PriorityQueue,这个Queue继承自AbstractQueue,是非线程安全的。
PriorityQueue的容量是unbounded的,也就是说它没有容量大小的限制,所以你可以无限添加元素,如果添加的太多,最后会报OutOfMemoryError异常。
PriorityQueue的底层实现就是Array,并且它是一个有序集合。
有序集合默认情况下是按照natural ordering来排序的,如果你传入了 Comparator,则会按照你指定的方式进行排序
PriorityBlockingQueue是一个BlockingQueue,所以它是线程安全的。
Comparable和Comparator的区别
Comparable是java.lang包下面的接口,lang包下面可以看做是java的基础语言接口,实现对象的natural ordering的排序。
Comparator在java.util包中,代表其是一个工具类,用来辅助排序的
DelayQueue的使用
DelayQueue是BlockingQueue的一种,所以它是线程安全的,DelayQueue的特点就是插入Queue中的数据可以按照自定义的delay时间进行排序。只有delay时间小于0的元素才能够被取出。
因为DelayQueue的底层存储是一个PriorityQueue,在之前的文章中我们讲过了,PriorityQueue是一个可排序的Queue,其中的元素必须实现Comparable方法。而getDelay方法则用来判断排序后的元素是否可以从Queue中取出。
SynchronousQueue详解
SynchronousQueue是BlockingQueue的一种,所以SynchronousQueue是线程安全的。SynchronousQueue和其他的BlockingQueue不同的是SynchronousQueue的capacity是0。即SynchronousQueue不存储任何元素。
也就是说SynchronousQueue的每一次insert操作,必须等待其他线性的remove操作。而每一个remove操作也必须等待其他线程的insert操作。
这种特性可以让我们想起了Exchanger。和Exchanger不同的是,使用SynchronousQueue可以在两个线程中传递同一个对象。一个线程放对象,另外一个线程取对象。
LinkedTransferQueue
是一个由链表结构组成的无界阻塞TransferQueue 队列。相对于其他阻塞队列,
LinkedTransferQueue 多了tryTransfer和transfer方法。
transfer方法:如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail 节点,并等到该元素被消费者消费了才返回。
tryTransfer方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer 方法的区别是tryTransfer 方法无论消费者是否接收,方法立即返回。而transfer 方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时再返回,如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
LinkedBlockingDeque
是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。
双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列, LinkedBlockingDeque 多了addFirst, addLast, offerFirst, offerLast,peekFirst,peekLast 等方法,以First 单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法add 等同于addLast,移除方法remove 等效于removeFirst。但是take 方法却等同于takeFirst,不知道是不是Jdk 的bug,使用时还是用带有First和Last后缀的方法更清楚。
在初始化LinkedBlockingDeque 时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在**“工作窃取”模式**中。
EnumMap
因为在EnumMap中,所有的key的可能值在创建的时候已经知道了,所以使用EnumMap和hashMap相比,可以提升效率。
同时,因为key比较简单,所以EnumMap在实现中,也不需要像HashMap那样考虑一些复杂的情况。
java的泛型
泛型是JDK 5引入的概念,泛型的引入主要是为了保证java中类型的安全性,有点像C++中的模板。
但是Java为了保证向下兼容性,它的泛型全部都是在编译期间实现的。编译器执行类型检查和类型推断,然后生成普通的非泛型的字节码。这种就叫做类型擦除。编译器在编译的过程中执行类型检查来保证类型安全,但是在随后的字节码生成之前将其擦除。
这里我再总结一下,协变和逆变只有在类型声明中的类型参数里才有意义,对参数化的方法没有意义,因为该标记影响的是子类继承行为,而方法没有子类。
当然java中没有显示的表示参数类型是协变还是逆变。
协变意思是如果有两个类 A<T> 和 A<C>, 其中C是T的子类,那么我们可以用A<C>来替代A<T>。
逆变就是相反的关系。
Java中数组就是协变的,比如Integer是Number的子类,那么Integer[]也是 Number[]的子类,我们可以在需要 Number[] 的时候传入 Integer[]。
接下来我们考虑泛型的情况,List<Number> 是不是 List<Integer>的父类呢?很遗憾,并不是。
我们得出这样一个结论:泛型不是协变的。
lambda中三种方法引用的方式
有三种方法可以被引用:
静态方法 调用外部类的静态方法,可以被转换成为
实例方法, 调用容器中类的实例方法,可以被转换成为
使用new的构造函数方法如:(TreeSet::new)
Stream peek和map
使用peek操作流,流中的元素没有改变。
使用map操作流,流中的元素有改变。
**注意:**peek对一个对象进行操作的时候,对象不变,但是可以改变对象里面的值
peek方法接收一个Consumer的入参. 了解λ表达式的应该明白 Consumer的实现类应该只有一个方法,该方法返回类型为void. 它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素.
map方法接收一个Function作为入参. Function是有返回值的, 这就表示map对Stream中的元素的操作结果都会返回到Stream中去.
最后更新于
这有帮助吗?