手动给docusaurus添加一个搜索
如果algolia不能自动配置的话,我教你手动给docusaurus添加一个搜索
新版博客用docusaurus重构已经有些日子了,根据docusaurus的文档上也申请了Algolia,想一劳永逸的解决博客的搜索问题。但是流水有意,落花无情。
algolia总是不给我回复,我只能对着algolia的申请页面仰天长叹。
正常情况的申请
按照docusaurus官方文档上说的,当我们需要搜索的时候,打开https://docsearch.algolia.com/apply/填一下申请,提交就行了。

但是可惜的是,我填好资料,点这个join the program很多次了,就是没有反应。
怎么办呢?我仔细检查了它的官方文档,看他的描述说是需要等待2个星期。但是2个星期实在太久了,在我们只争朝夕的今天,怎么行。
还好,我看到它还有一种手动上传的办法,笨是笨了点,总比没有的好。那就开始吧。
手动上传
首先我们得去Algolia上注册一个账号,然后在这里需要创建一个应用:
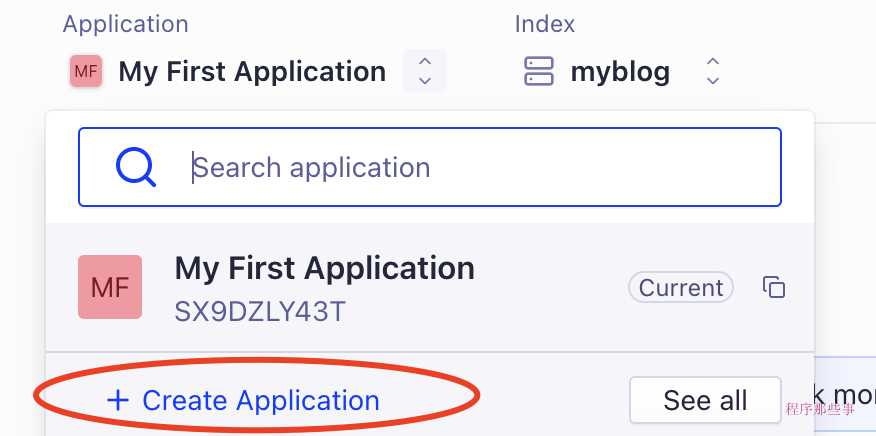
应用的旁边,需要创建一个index用来存储搜索数据:
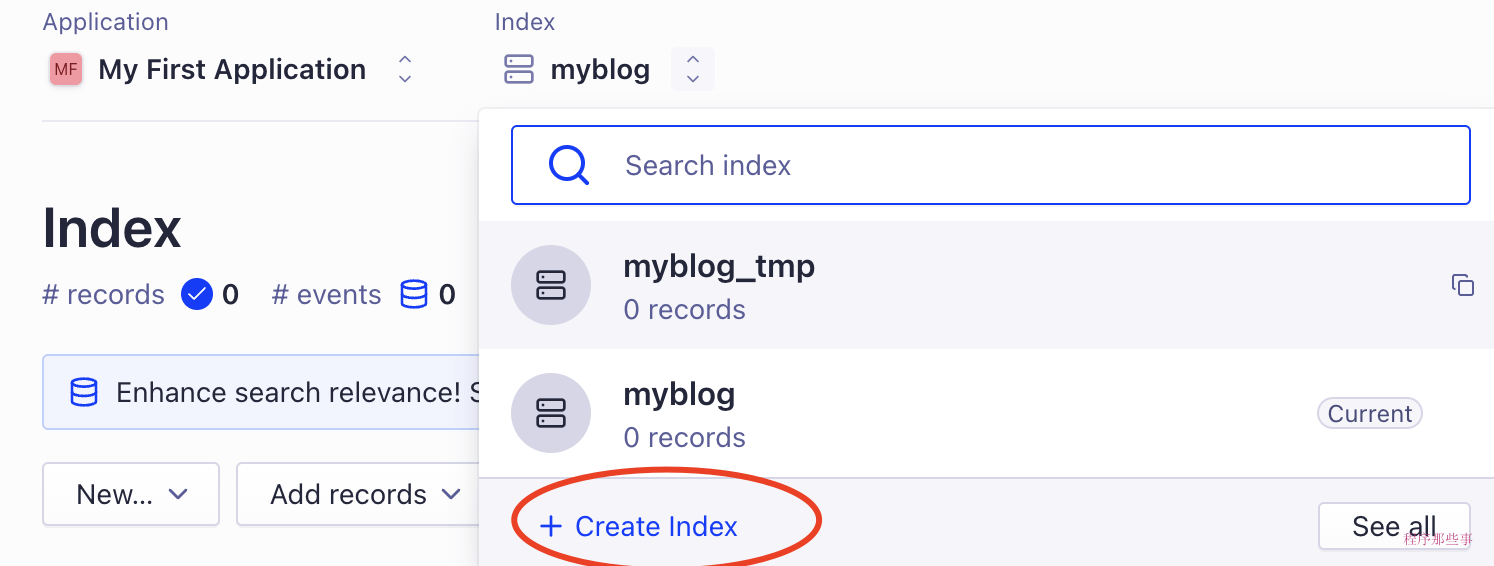
这样,前期的准备工作就做好了。
再在api设置中找到APPLICATION_ID和API_KEY。把他们保存到.env文件中:
APPLICATION_ID=YOUR_APP_ID API_KEY=YOUR_API_KEY
注意,这里的API_KEY最好是Admin API Key,因为会有一些权限需要。
如果是Admin API Key的话,记得不要分享给别人,这个key的权限比较大,可以删除和更新你的index数据。
设置配置文件
接下来,我们还需要一个配置文件。用来配置爬虫信息。下面是一个最基本的配置信息。
其中index_name就是我们刚刚在网站上创建的index_name。当DocSearch scraper程序跑起来的时候,你会发现有一个临时的index_name + _tmp 索引被创建。
别担心,在程序执行完毕之后,会把这个tmp index会替换最终的index。
start_urls包含的是要开始爬取的链接地址。爬虫会循环爬取链接里面的a标签,除非是遇到了stop_urls。另外爬虫不会爬取其他域名的链接。
selectors是用于创建记录层次结构的所有 CSS 选择器。其中text是强制,必须要有的。
如果你对不同的url有不同的selector方案,那么可以给不同的url配置不同的selectors_key,如下所示:
好了,基本的配置就这些了。
运行爬虫脚本
现在可以运行爬虫脚本了,这里有两个选择,一是跑docker,方便快捷。二是从源代码运行,这个就比较麻烦了。
这里我只是希望博客可以有搜索功能,所以源码什么的就算了吧,我们直接跑docker命令:
run -it --env-file=.env -e "CONFIG=$(cat flydean.conf | jq -r tostring)" algolia/docsearch-scraper
过一会就运行起来了。但是我们看看日志:
DocSearch: http://www.flydean.com/07-python-module/ 0 records) DocSearch: http://www.flydean.com/08-python-io/ 0 records) DocSearch: http://www.flydean.com/09-python-error-exception/ 0 records) DocSearch: http://www.flydean.com/06-python-data-structure/ 0 records)
Crawling issue: nbHits 0 for myblog
nb_hits表示的是DocSearch 提取和索引的记录数。
怎么是0 records?难道什么都没有爬到?
直觉是我的start_urls不太对,我们把它换成sitemap.xml再试一次:
还是同样的错误。
没办法,再去仔细读一下配置文件的说明。
终于发现了问题,原来这里的selectors写的有问题,#content header h1表示的是在ID为content的元素内部,寻找所有属于header类的元素,并在这些元素内部寻找所有的<h1>元素。但是在docusaurus V3版本中已经发生了变化。
我们把它改写成这样:
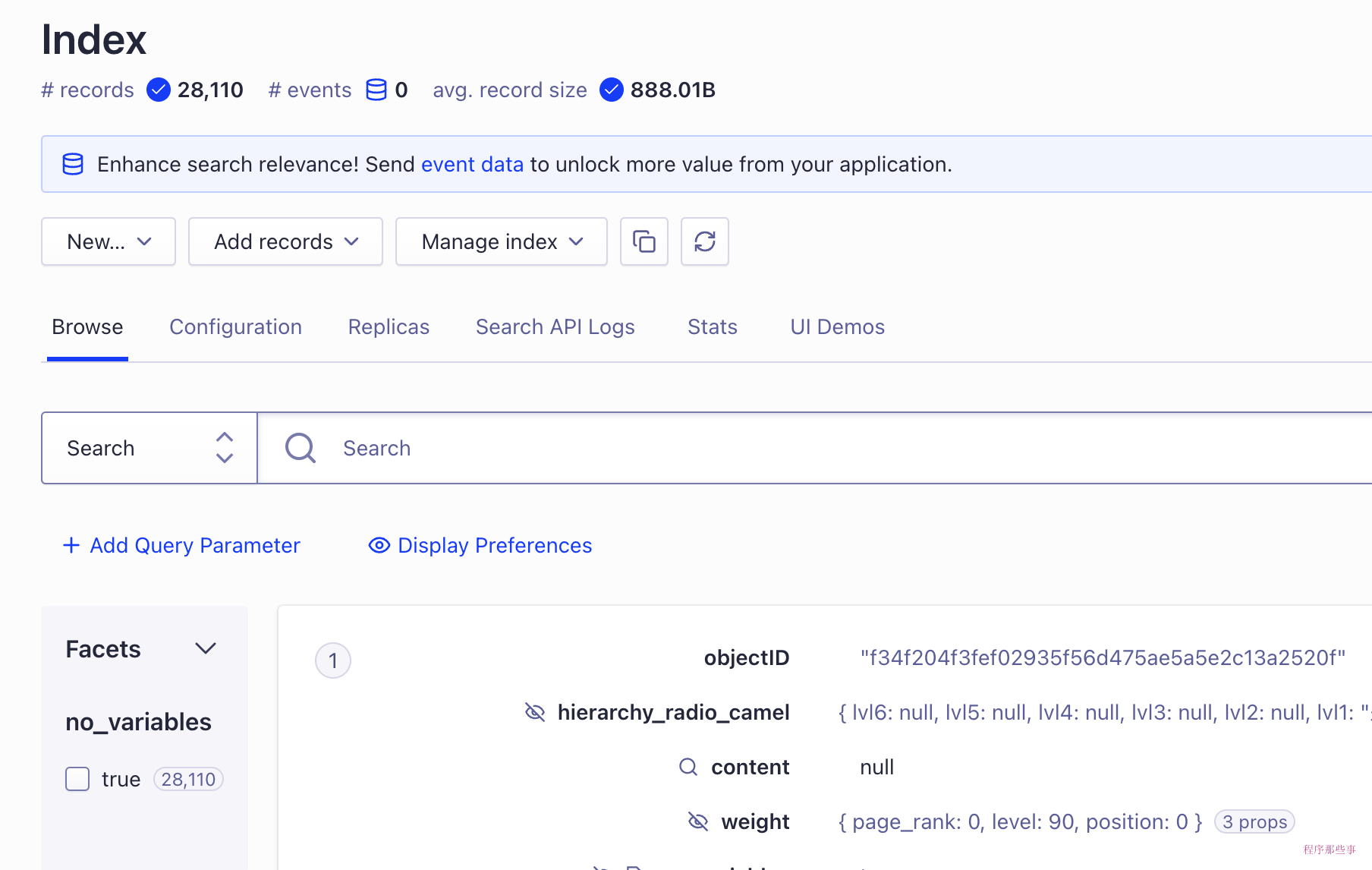
再运行一次,这次终于有数据了。
回到网站上看看,已经有数据上传上来了:
好了,我们在docusaurus.config.ts中配置一下,看看效果:
我们在网站上试试效果:
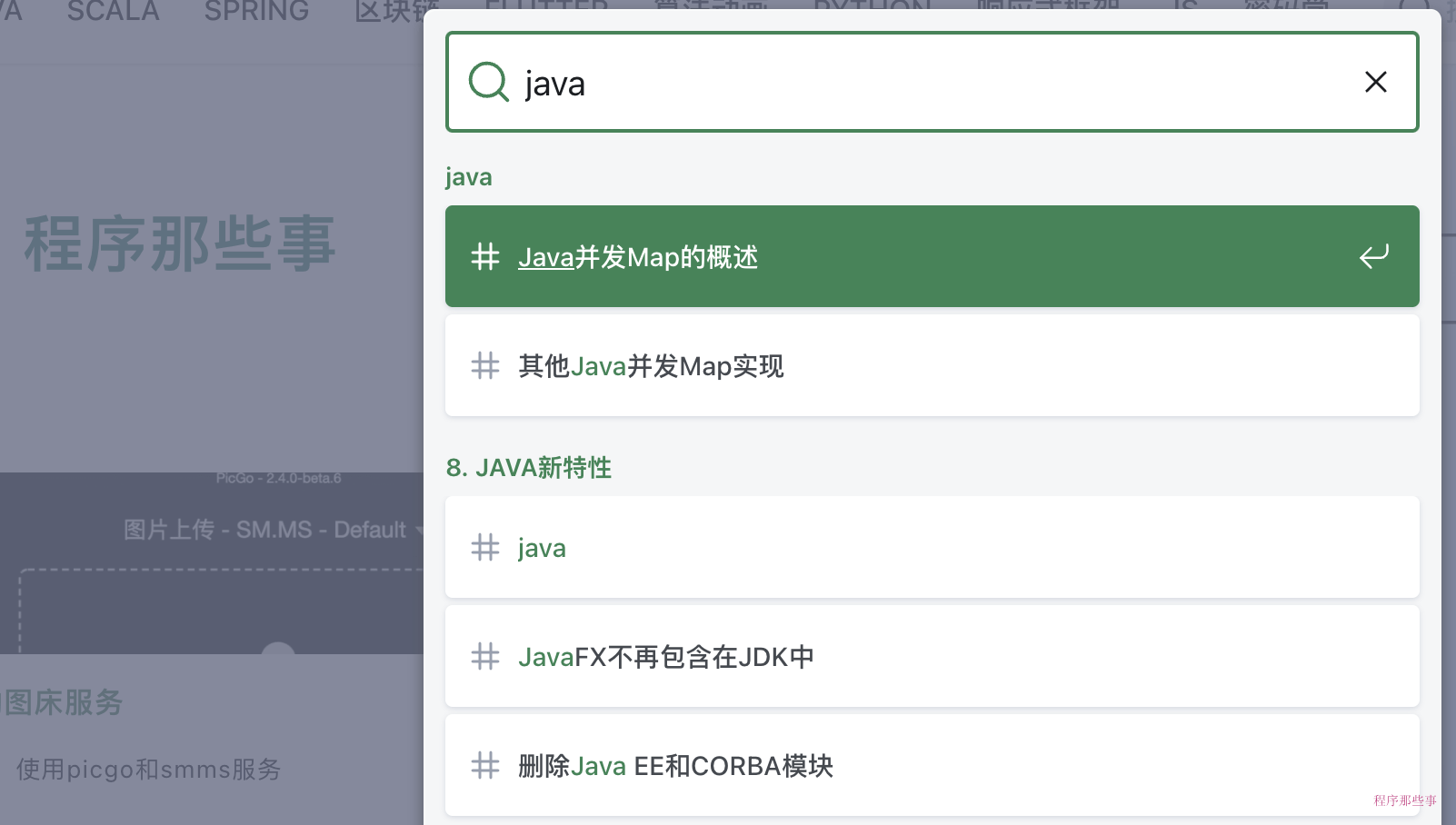
完美,遇到问题的小伙伴可以私信我哟!
最后更新于
这有帮助吗?